By accepting you will be accessing a service provided by a third-party external to https://www.incgmedia.com/
2D 圖像即能生成模型、動態,NVIDIA 於今年 SIGGRAPH 展示 Omniverse,以及 AI 與 GAN 結合的突破性科技
SIGGRAPH 大會是每年全球電腦繪圖與互動科技指標性會議,並由各開發與研究人員展示該領域的最新科技應用。由 ACM SIGGRAPH 所組織,自 1974 開始,每年都帶來開拓產業的革新科技。而提到電腦繪圖與互動科技,當然不能不提到科技龍頭 NVIDIA,本屆 NVIDIA 將重心集中於開創領域的虛擬協作平台 Omniverse,以及其延伸應用與 AI 及生成對抗網絡 GAN 技術結合下的新科技,跟映 CG 一起了解本次 SIGGRAPH 2021 大會中,NVIDIA 發表了哪些應用於 CG 產業的先進科技吧!
前往 Metaverse 世界,Omniverse 與 AI 科技的活躍
今年度 SIGGRAPH 2021,以虛擬平台的模式展開,至線上活動結束為止,已舉辦超過 775 個講座、對談環節,同時參與人更來自 100 個以上的各個國家。今年 NVIDIA 最受關注的莫過於兩大要點,前往虛擬世界 Metaverse 的基石 Omniverse,以及 AI 與 GAN 技術的深入運用。
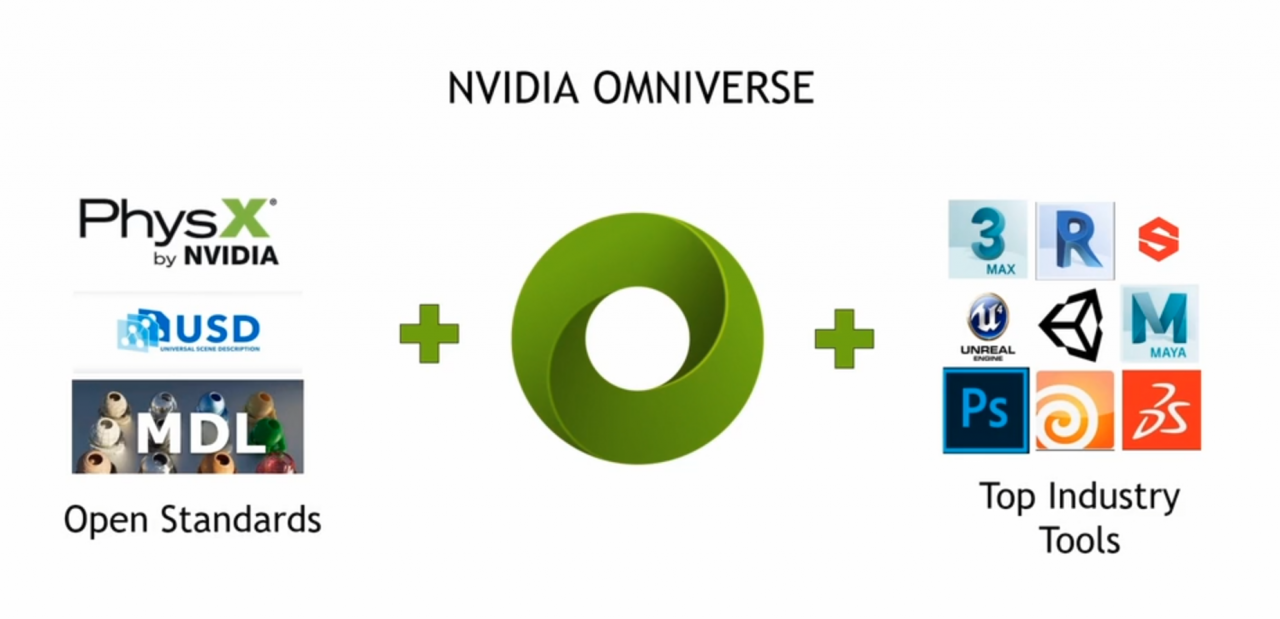
本次 NVIDIA 帶來其在 3D 深度學習與內容創作兩個層面的延伸應用。Omniverse 基底是以皮克斯的 USD ( Universal Scene Description )格式、材質定義語言 MDL 與物理模擬引擎 PhysX 等開源標準所建構,提供一個讓各領域的慣用軟體,能互通資料、協作的虛擬平台,讓領域間能即時合作,在 3D 創建上更加容易。不僅有針對設計、動畫、遊戲、機器人與自動駕駛汽車研發等,各領域需求的專屬外掛與擴充功能,其中 Omniverse Create 與 Omniverse Machinima 更是將為動畫與遊戲的製作帶來助益。
透過 NVIDIA 釋出的幕後影片,展示團隊如何在 Omniverse 中,創建於人工智慧技術大會 NVIDIA GTC 主題演講的視覺呈現,一改以往使用 PPT 的投影片呈現方式,他們充分使用 Omniverse 的相容性與即時協作的特色,讓 NVIDIA 團隊能夠省去過往來回通信的時間,即時且有效率地創作,從圖示到照片,皆透過 Omniverse 在各軟體上製作及渲染,打造精緻且流暢的展演,同時也整合最新的 AI 與 GAN 科技,以 CG 重現創辦人黃仁勳的虛擬身影,讓觀眾能一瞥精彩展演的幕後。
Omniverse 加速 3D 深度學習研究與內容創作
NVIDIA 除了根基於電腦繪圖的發展之外,過去十年的研究中,藉由深度神經網路(Deep Neural Networks)驅動的 AI 發展上,也有重大的突破與革新,而 Omniverse 更是在 AI 這個概念下設計出的產物,其中一個重要的應用是,產出能用以訓練 AI 的電腦合成數據。
藉由此項 AI 所驅動的科技如:
● StyleGAN ─以 GAN 技術為基底的 2D 藝術工具,讓藝術家能夠輕鬆地將原始作品圖的風格,結合各種參考風格並轉換。


令人期待的研發中運用:
● 3D 版的 StyleGAN ─能夠轉換既存 3D 模型的風格。這項深度學習網絡,能將參考模型的 Geometry 與材質變化,應用在原始模型上,創造出全新的 3D 模型。不僅能夠產生出無限的模型變化,同時也讓模型間的材質轉換變得容易。


● Lighting Estimation ─ 讓 3D 模型更容易融合進任何既存場景中。它會依據參考環境場景與物件,重新將 3D 模型打光,以符合場景環境。這項科技在 AR 等領域有極大的優勢。

● 廣泛的動畫與動態合成研究 ─ 例如以影片為基底生成的順暢動畫,動作估測、重新定向,以及產出依據物理的動態等。

Omniverse 與 AI 結合,讓藝術創作更容易
NVIDIA 更在 SIGGRAPH 2021 中,展示藝術家是如何藉著 Omniverse 與 GANverse3D,得以更容易地創作出令人驚豔的概念藝術作品。
● GANverse3D ─能夠從單張汽車的圖片,創建一個具有 Mesh 模型、材質與燈光的完整 3D 汽車模型。
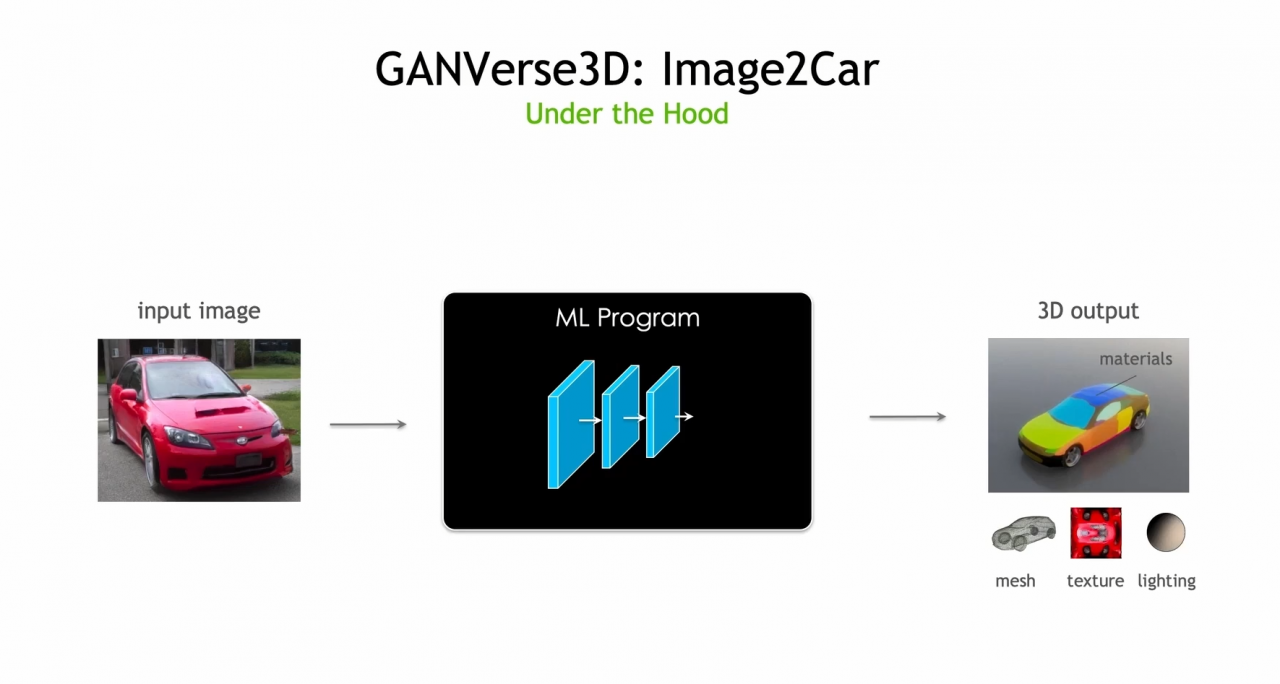
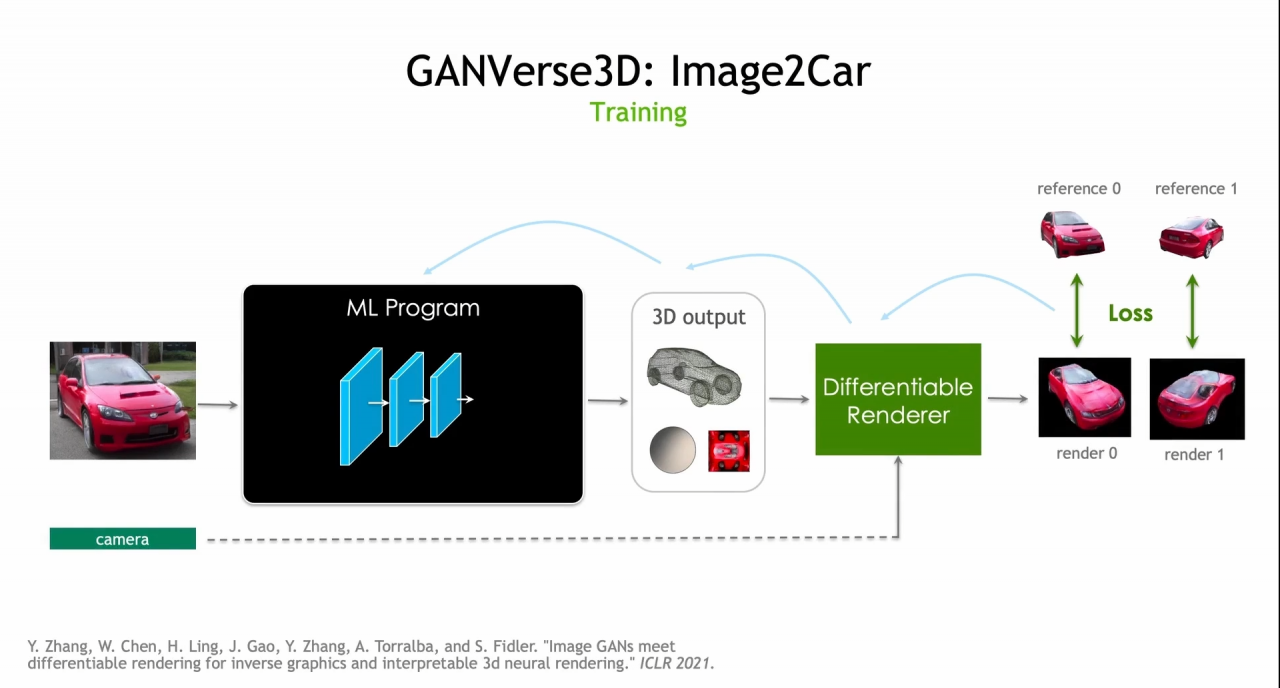
這項技術的生成則是為了讓程式能夠由真實的汽車照片,產生 3D 模型,一改傳統的機器學習 ( ML )方式,首先,讓 StyleGAN 模型能夠產生出大量的寫實電腦生成汽車圖片,接著利用已訓練好的 StyleGAN 生產器,創造有已知鏡頭角度或其他各種屬性的汽車圖片,即便這些圖片沒有潛在的 3D 模型,但仍足夠的資訊能夠用來訓練新的程式,同時憑藉 Differentiable Rendering 來訓練,讓它能夠由真實的照片,產生 3D 模型、燈光資訊與材質等。最後藉由與真實照片差異對比,與反向傳播算法(Backpropagation)方式訓練程式,再經由 Loss 的功能與參考對比,同時調整參數,改善最終輸出的成品樣貌。
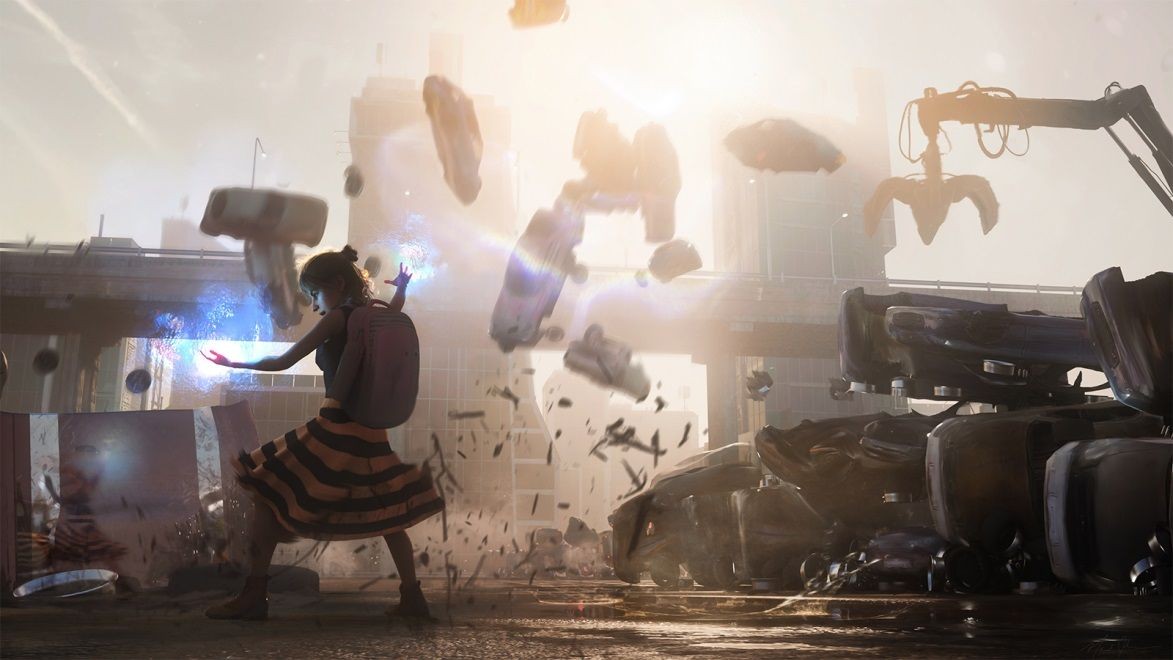
藝術家 Michael Johnson 創作的概念藝術作品
圖片出處:NV 新聞稿
展演中,呈現了 NVIDIA 創意團隊藝術家 Michael Johnson,他使用 GANverse3D 從 2D 的汽車照片,產生出大量的汽車模型,運用 Omniverse 的 Zero Gravity 功能,無需費時地親手擺放汽車堆,再加上物理模擬引擎 PhysX,則可以透過模擬的方式,演算出模型汽車的掉落的位置。他接著打光並開啟Path-tracing 渲染模式,收尾並完成這幅精緻概念藝術的場景,畫面中的主角則是使用 Omniverse 連結 Reallusion 的 Character Creator,當角色選擇與動作都創建好之後,便能輸出 USD 檔,迅速地放入場景中,最後將畫面匯入 Photoshop 調整並增加效果,完成一幅精緻的概念藝術。
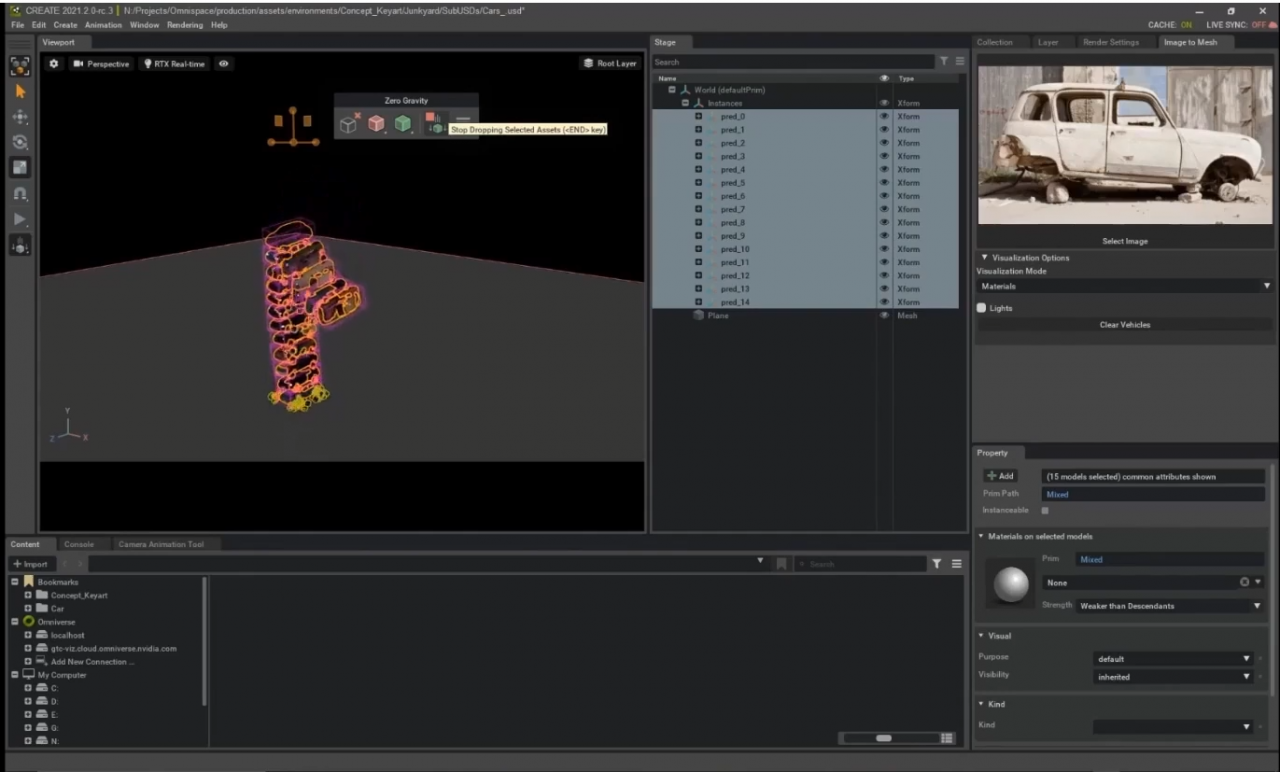
為了加速深度學習的開發,NVIDIA 多倫多 AI 實驗室更發展了一項 3D 深度學習研究的工具套組─ Kaolin,目前包含兩個主要工具,操作簡易提供低階 Python API,並於 PyTorch Tensor 執行的 Kaolin Library 與 Kaolin Omniverse App。

GANverse3D 運用 Mesh 來呈現 3D 資料,而 Kaolin Library 則能支援各種 3D 資料的呈現方式,且能在這之間互相轉換,包含 Mesh、Voxelgrids、 Point clouds、 SDFs ,與其他 GPU 的加速程式。
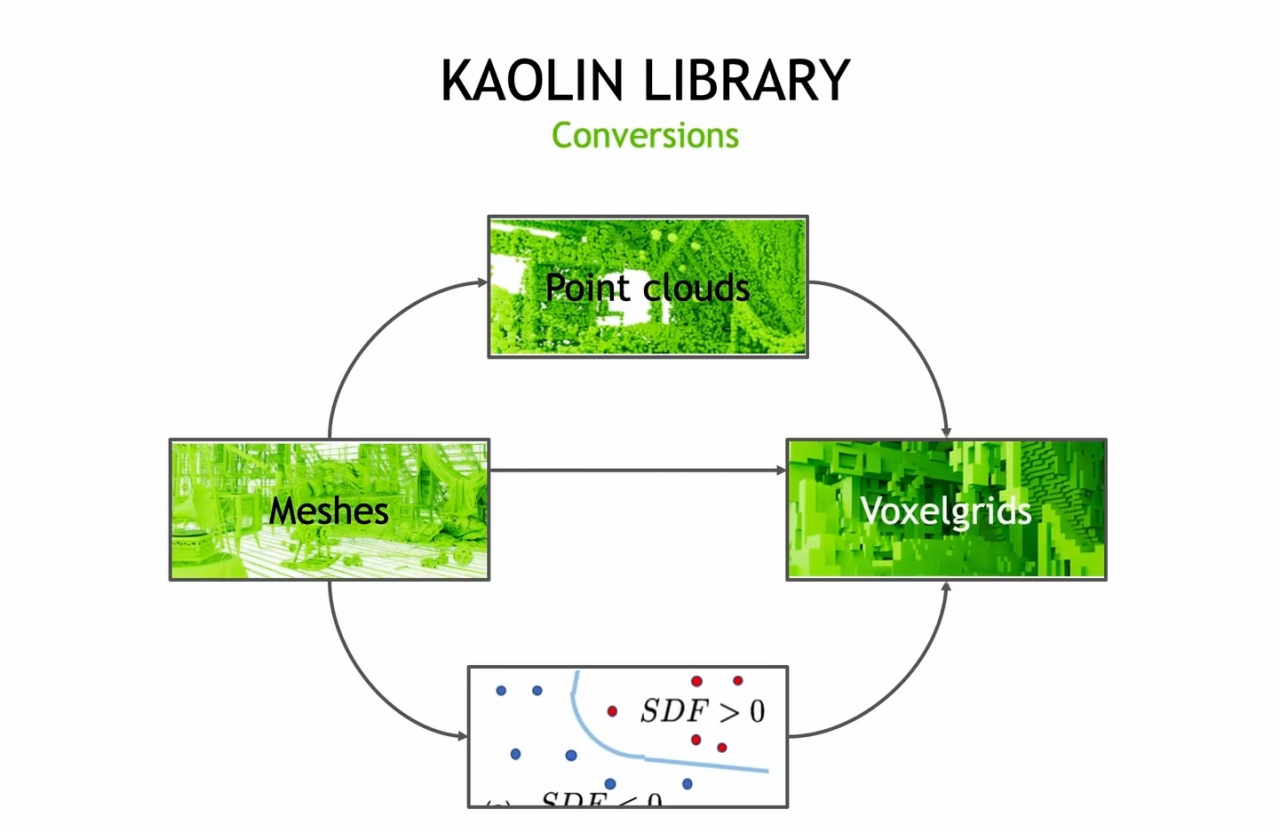
另一項 Kaolin Omniverse App,其目標則是讓訓練新一代的 3D 深度學習模型的過程變得更快速、更簡單。其中包含三項重要功能:資料生產器 Data Generator,能夠從既存的 3D 資產中創建大量的資訊組,提供工具,讓使用者能夠輕易地隨機化場景的範圍,例如:鏡頭、動作、燈光等的範圍,同時為了能夠符合各種專案的需求。Kaolin APP 被設計成能夠被使用者調整的架構,以達到使用者的需求。接著資料組視覺化 Dataset Visualizer,讓使用者能夠輕鬆地,在一個擁有適當燈光跟材質渲染的自然 3D 環境中,分析 Mesh、Voxelgrids、Point clouds 資訊。再加上 Training Visualizer。

AI 與 GAN 的結合,從單張圖片即時呈現動態畫面
Real-Time Live 是 SIGGRAPH 眾所注目的技術展示直播,每年由各開發及研究團隊帶來互動科技的即時展示,本屆拿下 Best In Show Award 大獎的,即是 NVIDIA 團隊所帶來的展演 「I AM AI:輕鬆打造人工智慧數位虛擬角色」。同時,NVIDIA 團隊也於次日的講座環節解說這個展演背後的科技。I AM AI 展演主要結合了 NVIDIA 的 AI 驅動技術:Audio2Face、 Vid2Vid Cameo 與 RAD-TTS,同時在 2D 藝術工具 StyleGAN 的輔助下,開啟更多可能性。
展演中,呈現了一個線上的面試情境,面試者將聲音經由網路傳輸至機器中,然後藉由 AI 驅動 Audio2Face,通過輸入聲音言語,在 3D 模型上,即時產出相應的對嘴、表情、臉部及頭部動作等。接著此 3D 的頭部模型動畫,會被匯進另一個 AI 深度學習模型 Vid2Vid Cameo ,將面試者的平面頭像照片,生成動態畫面,製作出面試者的虛擬角色。藉由這個過程,它僅透過聲音,即能夠驅動面試者照片的臉部及頭部動態。
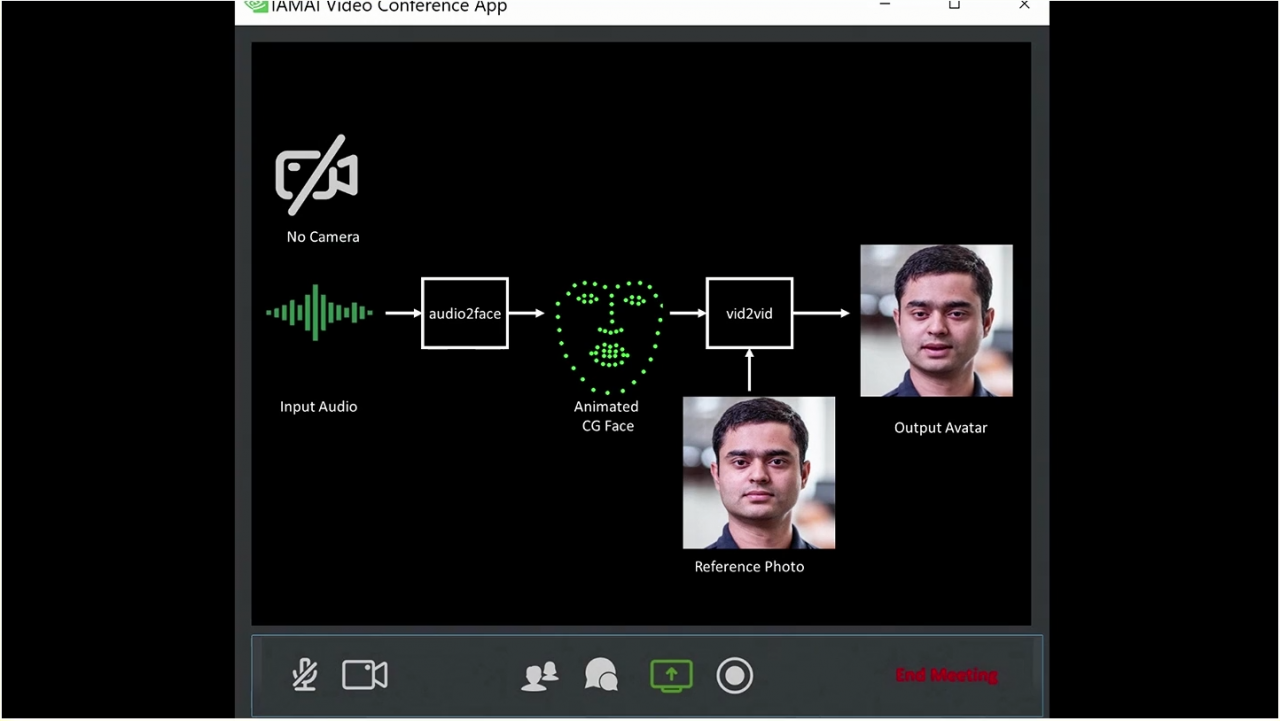
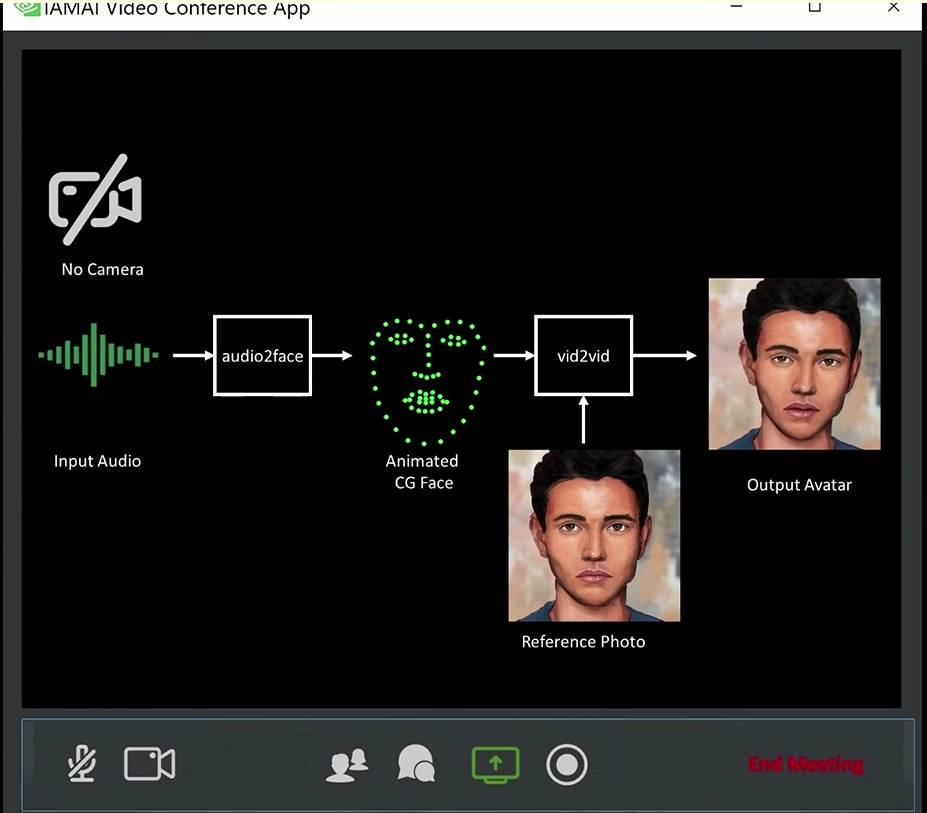
即使面試者戴著口罩,穿著輕便,但在視訊的面試畫面裡,透過聲音也能即時驅動他穿著較正式服裝的樣貌。同時不僅僅是能夠驅動真實的照片畫面,NVIDIA 團隊也展演了其能用於各種圖畫中,虛擬角色的應用,再加上 2D 藝術工具 StyleGAN,即能透過這個軟體,根據參考圖畫,產生無限多變化的數位虛擬角色。
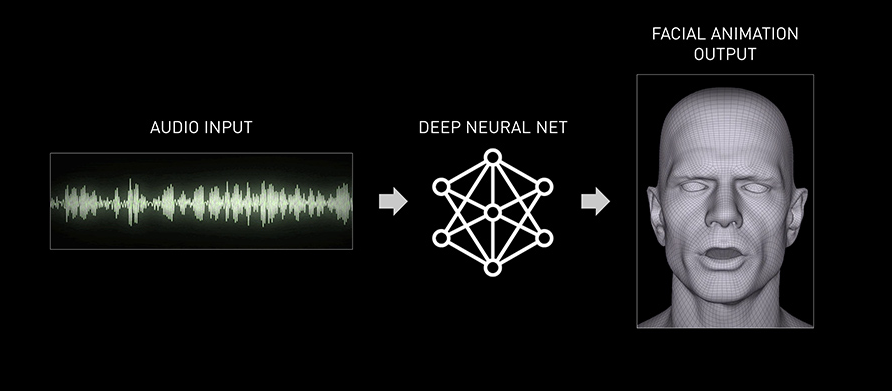
Audio2Face 是以 AI 為基礎的程式,能夠直接使用音訊,並產出豐富生動的臉部動畫。
圖片出處:NVIDIA 官網

Vid2Vid Cameo是以GAN技術為基底的深度學習模型,其降低傳輸頻寬與從單圖至動態轉換功能,不僅在各國遠距工作常態下,對於視訊會議的順暢將有很大的助益,在動畫與遊戲產業的應用也極有潛力。
圖片出處:SIGGRAPH
Vid2Vid Cameo主要包含以下三項功能:
• 影片畫面重建 Video Reconstruction ─ 僅需相較於傳統 H.264 傳輸的十分之一的頻寬,畫面呈現也更加清晰、順暢。相較於傳統視訊傳送完整 RGB 畫素的方式,此應用僅傳輸頭部動作與表情,並依據這些數據重現畫面。

• 頭部動作轉換 Head Rotation ─ 能調整畫面人像的頭部動作與視角,大幅改善以往,視訊等常見的視角不一問題,提升整體會議體驗。此技術只需要一張畫面,便能輕鬆產生出圖中人像的各種頭部動作。它與其他 Face Frontalization 技術相比,能更忠實呈現原始人物的正面長相,也不會有閃爍的畫面或雜點等常見問題。

• 動態轉移 Motion Transfer ─ 僅需一張圖片,即能完成傳輸並重現頭部各項動作,並可輕易地調整表情、臉的方向,與目光等,同時不只能夠將畫面頭像的動態,傳輸給相同人物,還能夠將動作傳輸給其他人,亦或是 2D、3D 角色。

在展演尾聲,面試者遇上周圍環境過於吵雜的情境,他將文字輸入深度學習模型 RAD-TTS,轉化成的擬真人聲,並將產出的聲音匯入 Audio2Face 中,緊接著匯入 Vid2Vid Cameo,即能夠達成從輸入文字驅動圖片中的角色臉部及頭部動態的成果。
● RAD-TTS 一個轉眼間即能將輸入的文字轉化成聲音,並能夠客製化,栩栩如生音訊生成的深度學習模型。圖片為將 RAD-TTS 與 Audio2Face 以及 Vid2Vid Cameo 結合運用的呈現畫面。
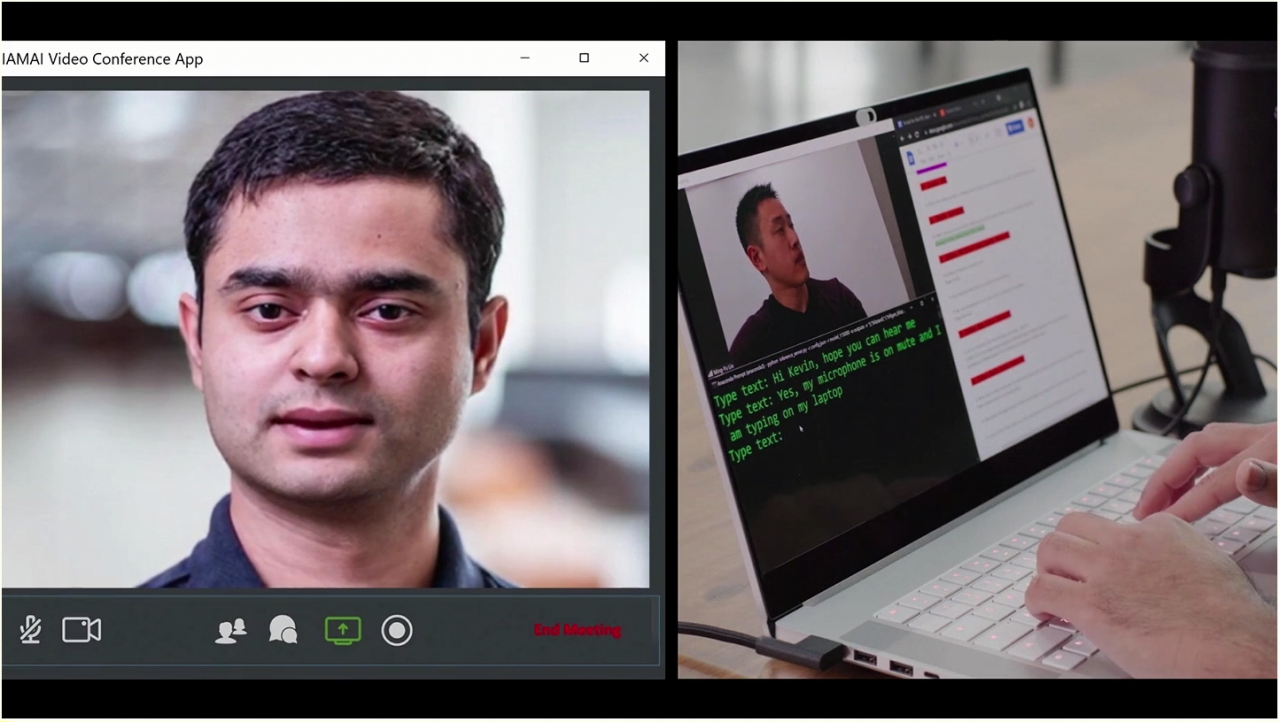
在 SIGGRAPH 2021 裡 NVIDIA 所帶來的技術突破,不僅提供能運用於企業間的遠端協作與會議的科技,AI 與 GAN 驅動的深度學習模型,能從僅僅單一圖片、音訊甚至文字,創造出充滿動態的角色臉部及頭部表演,更是為動畫與遊戲等,動態內容創作帶來更多的可能性。


